A semana pasada envieivos un email no que varios caracteres viñan substituídos por parellas de outros caracteres, e moitos de vós identificastes correctamente o problema: un erro de codificación. Hoxe quérovos falar deste erro, de por que ocorreu e dunha estratexia que podedes empregar para que non vos suceda a vós.
 Xogo de caracteres.
Xogo de caracteres.
Primeiro de todo, teño que falar de dous conceptos importantes. O primeiro é o “xogo de caracteres”, que é unha lista de caracteres recoñecidos por un sistema informático ou de telecomunicacións. Todos coñecedes o xogo de caracteres ASCII, pero teñen existido moitos xogos de caracteres en toda a historia das telecomunicacións e da informática. Por exemplo, IBM usa o xogo EBCDIC nos mainframes mentres que nas telecomunicacións o Baudot causou furor.
O segundo concepto importante é o da “codificación”, que especifica a maneira na que se representa cada carácter dun xogo de caracteres. Con ASCII, cada carácter vai asociado a un número que se representa como unha serie de sete símbolos binarios; EBCDIC ten unha codificación numérica como ASCII pero tamén unha codificación para tarxetas furadas; finalmente, Baudot usa cinco símbolos binarios para representar os seus caracteres.
Nos anos 80, 90 e primeiros dos 2000, nos países occidentais usabamos ASCII e outros xogos de caracteres “estendidos”, con caracteres propios das nosas respectivas linguas, que tiñan 256 caracteres. Os que usastes DOS lembraredes as páxinas de códigos 437 e 850, mentres que os de Windows e Linux estaredes máis afeitos a ISO-8859-1 e ISO-8859-15. Como estes xogos de caracteres tiñan 256 elementos, a súa codificación era moi simple: cada carácter ía nun byte.
Polo tanto, durante décadas, había unha cousa que os programadores sabiamos sen ningunha dúbida: unha cadea de texto era unha secuencia de bytes, cada byte contiña un carácter e cada carácter ía nun byte.
E despois chegou Unicode.
Unicode é un xogo de caracteres que contén (ou pretende conter) todos os caracteres de todos os sistemas de escritura da historia. Como son máis de 256 caracteres (a primeira versión de Unicode tiña 7 129), non se poden codificar todos os caracteres de Unicode cun só byte por carácter, así que é necesario empregar outra codificación.
Existen moitos sistemas de codificación para Unicode. Ata 1996, Unicode admitía un máximo de 65 536 caracteres, así que era habitual usar “caracteres anchos” de 16 bits. Isto funcionaba igual que a codificación de un carácter por byte, agás que cada carácter agora ocupaba dous bytes.
Cando o consorcio Unicode se decatou de que 65 536 caracteres non abondaban, tiveron que redefinir o estándar para admitir algo máis dun millón de caracteres. Tras este cambio, os “caracteres anchos” xa non eran grandes dabondo e algunha xente pasou a usar 32 bits por carácter, pero a maioría considerou que iso era un desperdicio así que seguiron a usar 16 bits cunha “trampa” para poder usar o millón de caracteres: algúns deles irían representados con dous bytes e outros con catro (dous números de 16 bits).
Un inconveniente destas codificacións de 16 e 32 bits é que non son compatibles con ASCII e era difícil modificar os programas que xa existían para que usaran caracteres anchos no canto de caracteres de 8 bits. Ademais, a maioría dos documentos e textos usaban só os 128 caracteres ASCII, así que se usaran caracteres de 16 bits serían moito menos eficientes no seu uso de memoria. Para solucionalo, Ken Thompson e Rob Pike inventaron UTF-8, unha codificación para Unicode compatible con ASCII e con largura variable.
En UTF-8, os primeiros 128 caracteres de Unicode ocupan un byte (igual que en ASCII), os seguintes 1 920 ocupan dous bytes, os seguintes 61 440 ocupan tres, e o millón restante ocupa catro bytes. Usando a codificación UTF-8, un programa feito para ASCII pode manipular ficheiros Unicode e viceversa.
UTF-8 é, hoxe en día, a codificación máis usada e funciona bastante ben, pero ás veces hai problemas cando un programador ou unha linguaxe de programación non sabe distinguir entre unha cadea de texto e unha secuencia de bytes.
Moitas linguaxes de programación non fan esa distinción. Por exemplo, en C un char contén un byte e unha cadea de texto é un array de char; en C++ un string tamén é unha secuencia de char. En PHP, o tipo string é unha secuencia de bytes. Ningunha desas linguaxes especifica unha codificación para a cadea de texto, así que depende totalmente da codificación que empregue o sistema operativo.
Algunhas linguaxes modernas si que distinguen. Por exemplo, Go ten un tipo byte (que contén un byte) e un tipo rune (que contén un carácter Unicode) e unha cadea de texto é unha secuencia de runes, non de bytes. Rust tamén usa u8 para os bytes e char para os caracteres. Java tamén ten byte e char.
Python é un caso curioso porque Python 2 non facía esta distinción pero Python 3 si. En Python 2 era normal meter unha secuencia de bytes nunha variable de tipo str; en cambio, en Python 3 as secuencias de bytes van nun tipo bytes e o tipo str contén unha secuencia de caracteres Unicode.
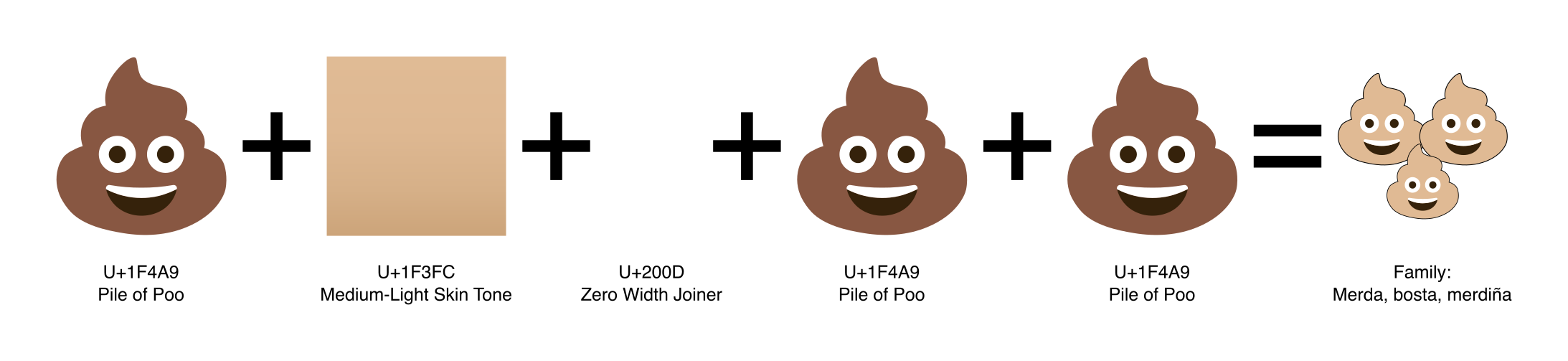
Inciso: Na realidade, Unicode non define caracteres senón “codepoints” que poden ser caracteres ou modificadores, e un carácter pode estar representado por un ou por varios codepoints, un detrás do outro. Por exemplo, “é” pode ser un só carácter “é” ou unha combinación de “e” e un til “◌́”.
Ata mediados da década de 2010, moitos sistemas operativos e linguaxes de programación non trataban correctamente estes caracteres combinados. Que ocorreu daquela para que se animaran a arranxalo? Ocorreu que se popularizaron os emoji e a xente quería telos nos seus teléfonos e aplicacións.
Os emoji están en Unicode e moitos deles están formados por combinacións de codepoints. Algúns exemplos son: os emoji das bandeiras 🏳️🇬🇱🏴, as variacións na cor da pel 👍🏻👍🏽👍🏿 ou sexo 👩🎓👨🎓 e os distintos tipos de familia 👩👦👨👩👧👨👨👧👩👩👦👦.
Polo tanto, incluso nas linguaxes que fan a distinción da que falaba enriba, un carácter Unicode pode estar repartido entre varios elementos de tipo
runeoucharou o que corresponda. Por se pensabades que Unicode era sinxelo.
Ás veces os programadores tampouco saben distinguir entre bytes e caracteres e empérranse en construír cadeas de texto byte a byte ou en acceder a bytes individuais. Iso é o que ocorrera cando recibistes ese email titulado “Teño o ordenador escacharrado”: o texto do email quedou gardado cunha codificación UTF-8 e cando lle dei ao botón de “volver a enviar”, o programa leu o texto da campaña orixinal tratando cada byte como un carácter separado no canto de descodificalo.
Para evitar caer neste problema tedes que vos afacer a distinguir entre secuencias de bytes e cadeas de texto. Considerade sempre que unha secuencia de bytes consiste en datos binarios, e para convertela nunha cadea de texto é necesario descodificala.
Cando precisedes de tratar cunha secuencia de bytes no voso programa, nunca a almacenedes nunha variable de tipo “cadea de texto”. Se a linguaxe que escolledes non vos dá un tipo axeitado para iso, creade un. Por exemplo, en C++ eu sempre trato as secuencias de bytes como std::vector<uint8_t>, non como std::string.
No correspondente ás cadeas de texto, usade sempre o tipo “cadea de texto”, non “secuencia de bytes”. Tratádeas carácter a carácter, non byte a byte, e lembrade sempre que estades a tratar con Unicode, non con xogos de caracteres pequeneiros como ISO-8859-15. Hai máis de 256 caracteres!
Finalmente, cando recibades texto de fóra para o voso programa (dun ficheiro, dunha base de datos, dunha páxina web, dun servizo RPC, …), asegurádevos de que chega coa codificación que vós esperades e configurade sempre a codificación de xeito explícito. Non usedes os valores por defecto do sistema, que unha vez tiven un problema moi difícil de diagnosticar por culpa diso.
Hoxe quedoume unha Folla ben longa. Espero que a lerades con gusto, que vos sexa útil e que nunca máis teñades problemas de codificación cos vosos programas.
As ilustracións desta Folla son de elaboración propia.