Dicía Dijkstra, o famoso teórico da informática, que os que aprenderon a programar con BASIC teñen a cabeza irremediablemente podre. Eu son un deses e non sei como de podrecida está a miña testa, pero o que si é certo é que tardei moito tempo en saber onde vai o contido das variables que uso nos meus programas. “Na memoria, Jacobo”, dicides, pero o conto é un pouco máis complicado. A ver se con esta Folla lle evito a confusión a alguén.
 Problemas coa memoria.
Problemas coa memoria.
Nos primeiros tempos da informática, os programas gardaban os seus datos e variables en lugares predeterminados da memoria. O programador, por exemplo, sabía que o código postal estaba na posición de memoria 0170 e a suma total estaba na posición 0210, e os seus programas accedían directamente a esas posicións de memoria para manipular os datos que contiñan.
Cando se inventou o código ensamblador, os programadores pasaron de tratar con posicións na memoria a usar nomes que representaban esas posicións, pero o conto era o mesmo: o código postal agora estaba en CODPOST, pero ese nome seguía a representar a posición de memoria 0170.
Este modelo é moi sinxelo de usar e de aprender. Cando aprendín BASIC dixéronme que o nome de cada variable representaba unha posición na memoria, e ese foi o modelo mental que tiven (e me serviu) durante moitos anos. Cando tentei aprender Pascal e C, porén, este modelo foi un estorbo, porque xa non era válido.
Xa me daba dor de cabeza o feito básico de que nesas linguaxes hai que declarar as variables antes de usalas e non abonda con usalas, como en BASIC. Cando chegou o momento de falar de punteiros, xa me mataron. Cantas veces collía eu un punteiro a unha variable e despois, cando o quería usar, resultaba que ese punteiro dirixía a un enderezo na memoria que contiña datos aleatorios e non o que eu esperaba.
Variables globais
Nas linguaxes de programación modernas, as variables globais adoitan ir en posicións de memoria fixas, aínda que, normalmente, esas posicións de memoria van escollidas polo compilador, non directamente por nós.
É moi simple programar usando só variables globais: por iso nas versións “clásicas” da linguaxe BASIC todas as variables eran globais. Isto ten limitacións, claro, pero así e todo moita xente logrou facer programas e xogos moi grandes e complexos nesa linguaxe.
Para un exemplo desas limitacións, imaxinade que tedes unha subrutina A que ten unha variable b asignada á posición de memoria 0740. Se no medio de executar a subrutina A facedes unha chamada (directamente ou indirectamente) á mesma subrutina A, as correspondentes variables b de cada execución de A van estar asignadas á mesma posición de memoria. Se non tedes coidado, as dúas execucións da subrutina hanse estorbar unha á outra.
Para evitar este problema é necesario ter un sistema de “variables locais” no que a variable b da primeira chamada á subrutina A está asignado a unha posición de memoria diferente á da variable b da segunda chamada.
Variables locais
Para ter variables locais é necesario argallar unha maneira de organizar e usar memoria dinamicamente (no que unha variable pode ter diferentes enderezos en cada momento) e non estaticamente (no que sempre ten o mesmo enderezo). Na maioría das plataformas, isto acadouse mediante o uso dunha rima1 (“stack”, en inglés).

Unha rima, no mundo dos procesadores, consiste nunha rexión de memoria e un rexistro (normalmente chamado SP) que contén un enderezo dentro desa rexión de memoria.
O procesador ten dúas instrucións para manipular a rima: PUSH, que engade un elemento, e POP, que extrae o último elemento que se engadiu. As dúas instrucións modifican SP para que apunten ao seguinte ou anterior enderezo, respectivamente2.
; Un exemplo de uso da rima nun procesador 8086. Intercambia AX e BX.
MOV AX, 1234h ; Garda o valor 1234h no rexistro AX
MOV BX, 5678h ; Garda o valor 5678h no rexistro BX
PUSH AX ; Garda o contido de AX (1234h) na rima
PUSH BX ; Garda o contido de BX (5678h) na rima
POP AX ; Extrae o último elemento da rima (5678h) a AX
POP BX ; Extrae o último elemento da rima (1234h) a BX
Ademais de gardar valores, a rima tamén serve para que as subrutinas poidan retornar ao sitio correcto cando rematan. A instrución CALL fai un PUSH do enderezo da instrución seguinte ao CALL, e a instrución RET fai un POP dese enderezo e salta a el. Grazas a isto, o programa pode facer tantas chamadas a subrutina como caiban na rima.
0100 CALL 0200 ; fai push de 0104 e salta ao enderezo 0200
0104 NOP ; a execución continúa trala chamada á subrutina
...
0200 NOP ; subrutina!
0201 RET ; fai pop, obtendo 0104, e salta a ese enderezo
Outra utilidade da rima nas subrutinas é a almacenaxe de variables locais. Aínda que existan as instrucións especializadas PUSH e POP, non é obrigatorio utilizalas: un pode manipular directamente o rexistro SP para facer un oco na rima (como se se fixera un PUSH de moitos datos) e despois acceder directamente á memoria correspondente a este oco. A única condición é que, antes de saír, a subrutina ten que desfacer o oco e deixar a rima como estaba antes3.
Unha subrutina pode asignar ás súas variables enderezos que pertencen ao oco que fixo na rima; desta maneira, esas variables son locais, xa que só están dispoñibles mentres se executa a subrutina e, se hai varias chamadas á mesma subrutina, cada chamada ten o seu propio oco na rima ao que as súas correspondentes variables están asignadas.
Un inconveniente da rima é que o seu tamaño é bastante limitado. Ás veces, un programador quere reservar uns poucos megabytes para un array e o compilador non o admite ou o programa falla cun “stack overflow”. É necesario usar outro mecanismo para facer isto, pero antes de falar del, teño que mencionar os punteiros e as referencias.
Punteiros e referencias
Algunhas linguaxes teñen punteiros (C), outras teñen referencias (Java), outras teñen as dúas cousas (C++) e outras non teñen ningunha das dúas (BASIC).
 Punteiro.
Punteiro.
Un punteiro é unha variable que contén o enderezo dunha posición en memoria. O punteiro ten un tipo asociado (“punteiro a int”, “punteiro a string”) que nos permite acceder a esa memoria como se fora unha variable normal do programa.
Nunha linguaxe con punteiros, o programador ten que usar unha sintaxe especial para distinguir se está operando co enderezo contido no punteiro ou coa memoria á que este enderezo apunta.
Unha referencia tamén contén un enderezo dunha posición en memoria, ten un tipo asociado e permite acceder a esa memoria como se fora unha variable. Cunha referencia, porén, o programador non pode manipular directamente o enderezo: só a memoria á que apunta.
Moitas linguaxes teñen un operador que devolve o enderezo dunha variable; este enderezo pode despois asignarse a un punteiro ou a unha referencia para poder operar coa variable orixinal a través do punteiro ou referencia.
Os punteiros danlle moita dor de cabeza aos programadores que teñen pouca experiencia. Por un lado, ás veces é complicado razoar se unha expresión de punteiros opera cun enderezo ou co contido dese enderezo; por outro, ás veces un acaba tendo punteiros que conteñen enderezos non válidos, enderezos de variables locais pertencentes a subrutinas que xa saíron, e outras cousas semellantes, e é difícil saber por que.
A morea
Ata agora falei de dúas maneiras de organizar a memoria que vai asignada ás variables. A primeira maneira consiste en darlle un enderezo fixo a cada variable, como un escritorio con caixóns no que cada cousa ten o seu sitio.
A segunda maneira consiste en usar a rima, como se tiveramos unha bandexa con papeis no escritorio: engadimos papeis na cima ou quitámolos da cima.
A terceira maneira de organizar a memoria é a morea (“heap”, en inglés). Como o seu nome indica, é como botar os papeis todos nunha morea na mesa e ilos poñendo ou sacando segundo conveña.
 Morea.
Morea.
A morea é un bloque de memoria que o sistema operativo pode facer medrar segundo precise o noso programa. A linguaxe de programación ofrece unha función para reservar espazo na morea e outra para liberar un bloque de espazo reservado para podelo reutilizar máis adiante.
// Exemplo de uso da morea en C
void *f = malloc(100 * 1024 * 1024); // Reserva cen megabytes
// ... fai cousas cos cen megabytes ...
free(f); // Libera os cen megabytes
Os bloques de memoria reservados na morea perduran ata que se liberen: dá igual se a subrutina que os reservou xa rematou ou non. Isto fai posible, por exemplo, crear funcións que devolven bloques de memoria ou que manipulan estruturas de datos complexas.
Esta flexibilidade tamén trae problemas: ás veces, os programadores esquecen liberar os bloques de memoria que reservaron, dando lugar a perdas de memoria (“memory leak”). Outras veces, tratan de acceder a un bloque de memoria despois de liberalo (“use after free”). Algunhas veces esquecen reservar memoria antes de acceder a ela, e outras veces libérana dúas veces.
No mundo das linguaxes da programación hai dúas filosofías para xestionar a morea. Na primeira filosofía, o programador ten que levar conta de que memoria está reservada e que memoria ten que ser liberada. C, Pascal e C++ seguen esta filosofía; na práctica, é moi difícil non trabucarse nunca, polo que moitos programas feitos nesas linguaxes teñen moitos dos erros que mencionei no parágrafo anterior.
Na segunda filosofía, o propio programa leva a conta do uso da memoria e utiliza un procedemento chamado “recollida do lixo” (“garbage collection” en inglés) para liberar a memoria da que xa non se precisa. Desta maneira, o programador non ten que pensar no asunto e tampouco pode cometer erros pola súa culpa. A maioría das linguaxes modernas segue esta filosofía: Java, Python, C#, Go, Ruby, Erlang, …
A recollida de lixo ten mala fama porque, moitas veces, causa lentitude ou interrupcións periódicas da execución dun programa, pero evita moitos erros de programación.
 Xa que falamos de recollida do lixo, aquí vai todo o que cortei dos sucesivos borradores desta Folla.
Xa que falamos de recollida do lixo, aquí vai todo o que cortei dos sucesivos borradores desta Folla.
Conclusión (xa vai sendo hora)
Como xa dixen, moitas das dificultades que tiven eu para entender onde estaba a miña memoria viña da combinación de punteiros, variables globais, locais e a morea.
As variables globais residen en posicións fixas da memoria. Se obtedes o enderezo dunha delas e o poñedes nun punteiro ou referencia, ese punteiro sempre vai ser válido porque a variable non vai desaparecer nin mudar de sitio.
As variables locais, porén, residen na rima, e só son válidas mentres se executa a subrutina á que pertencen. Se poñedes o enderezo dunha delas nun punteiro e despois saídes da subrutina, ese enderezo ha deixar de ser válido.
Finalmente, as variables reservadas na morea son válidas ata que se liberen. O principal problema que podedes ter é se gardades un punteiro a unha delas e tratades de acceder a ela despois de liberala.
Nalgunhas linguaxes modernas, as variables locais non van sempre na rima. Por exemplo, a linguaxe Go fai unha análise das variables e valores definidos dentro dunha función e, se detecta que o programador pode acceder a esa variable desde fóra da subrutina, reserva a memoria na morea no canto da rima.
Dunha maneira ou da outra, se tedes problemas cos vosos punteiros, comprobade que a memoria á que apuntan está dispoñible usando as regras de enriba. Igual levades unha sorpresa.
-
Botei moito tempo a procurar unha boa tradución en galego para “stack”.
“Pila” é castelanismo, pois en galego é un dispositivo xerador de electricidade. “Pía” é un recipiente.
O Estraviz recolle “pilha”, pero non atopo unha voz equivalente noutros dicionarios galegos. No portugués si: procurei “pilha” no Priberam e ofreceume os sinónimos “resma” e “rima”.
Todos os dicionarios galegos aos que teño acceso dinme que “resma” é un conxunto de cincocentas follas de papel, pero todos eles tamén me din que “rima” é un conxunto de cousas postas unhas enriba das outras. Adicionalmente, o dicionario da RAG ofrece “rima” como sinónimo de “monte”, “montón” e “morea”.
En consecuencia, adoptei “rima” como tradución de “stack”. Xa veredes máis tarde por que non optei por “morea”. ↩︎
-
Normalmente, un esperaría que o valor de
SPcomezara no enderezo máis baixo da rima e fora subindo con cadaPUSHe baixando con cadaPOP. Porén, en x86 isto é ao revés: no principio,SPcontén o enderezo máis alto da rima e baixa con cadaPUSHe ascende con cadaPOP.Isto é moi común en moitos procesadores, pero o principal motivo polo que se fixo así en x86 é compatibilidade cos procesadores de 8 bits e co sistema operativo CP/M. Estes procesadores só podían xestionar 64 kilobytes de memoria, así que o código do programa, os datos e a rima tiñan que caber todos neses 64 kilobytes.
Normalmente, o código comezaba nos enderezos máis baixos da memoria. Por exemplo, podía ir do enderezo
0100hata o1FFFh. Despois do código tiñan que vir os datos e a rima. O normal era poñer os datos xusto despois do código; neste exemplo comezarían no enderezo2000hcara a arriba.A cuestión é onde se pon a rima. Ao contrario que o código, os datos non teñen un tamaño fixo e poden medrar ou reducirse segundo as necesidades do programa. Polo tanto, como non se coñece o derradeiro enderezo dos datos, non se pode poñer a rima xusto despois deles.
A solución consiste en poñer a rima no final da memoria: comeza no derradeiro enderezo e despois esténdese cara a abaixo segundo aumenta o seu tamaño. Por iso o valor de
SPdescende ao engadir elementos na rima: canto máis grande é, máis abaixo chega.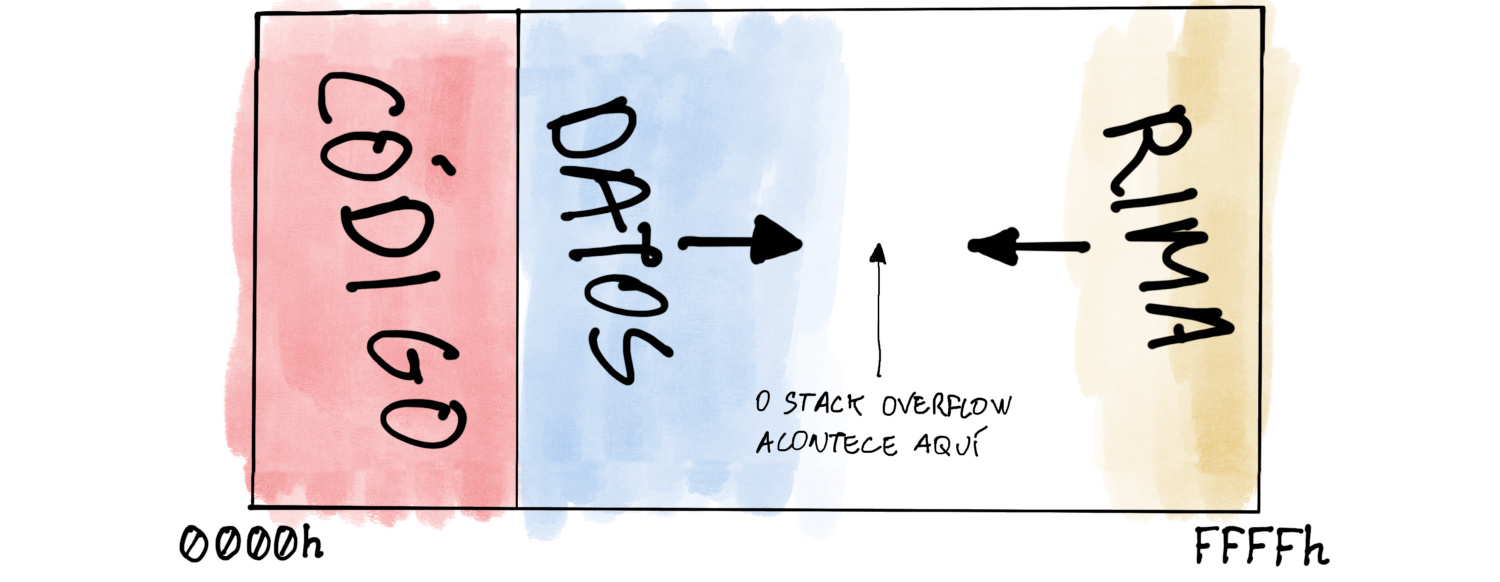
Como os deseñadores do 8086 querían poder usar CP/M e moitos dos programas que funcionaban nese sistema operativo, aplicaron o mesmo sistema. É tamén o mesmo motivo polo que o 8086 dividía a memoria en segmentos de 64 kilobytes, pero esa é outra historia. ↩︎
-
En x86 pódese reservar espazo na rima restando o seu tamaño do rexistro
SP(sigo a usar o 8086 para os exemplos). A arquitectura x86 ofrece outro rexistro,BP, para gardar o valor orixinal deSPe poder acceder ás variables e argumentos sen ter que levar a conta de canto espazo se reservou.Por exemplo, esta subrutina en ensamblador reserva 64 bytes para as variables locais:
_subrutina: PUSH BP ; garda o valor antigo de BP MOV BP, SP ; asigna o valor de SP a BP SUB SP, 64 ; reserva 64 bytes na rima restando 64 de SP ; agora as variables locais están entre [BP - 64] e [BP - 1] ; se hai argumentos, están en [BP + 4], [BP + 6], etc. ; ... MOV SP, BP ; restaura o valor antigo de SP léndoo de BP ; (desfai a reserva de 64 bytes) POP BP ; restaura o valor antigo de BP ; agora a rima está igual que no principio da subrutina RETSe desensamblades un programa feito en C para a arquitectura x86, case sempre vai ter esta feitura. ↩︎