Se tedes un servizo en produción, supoño que tedes un sistema de monitorización para saber canta latencia hai, a memoria que está ocupada ou a carga de CPU. Seguramente tamén veña con varias gráficas de liñas de cores e uns poucos números que resumen esas estatísticas.
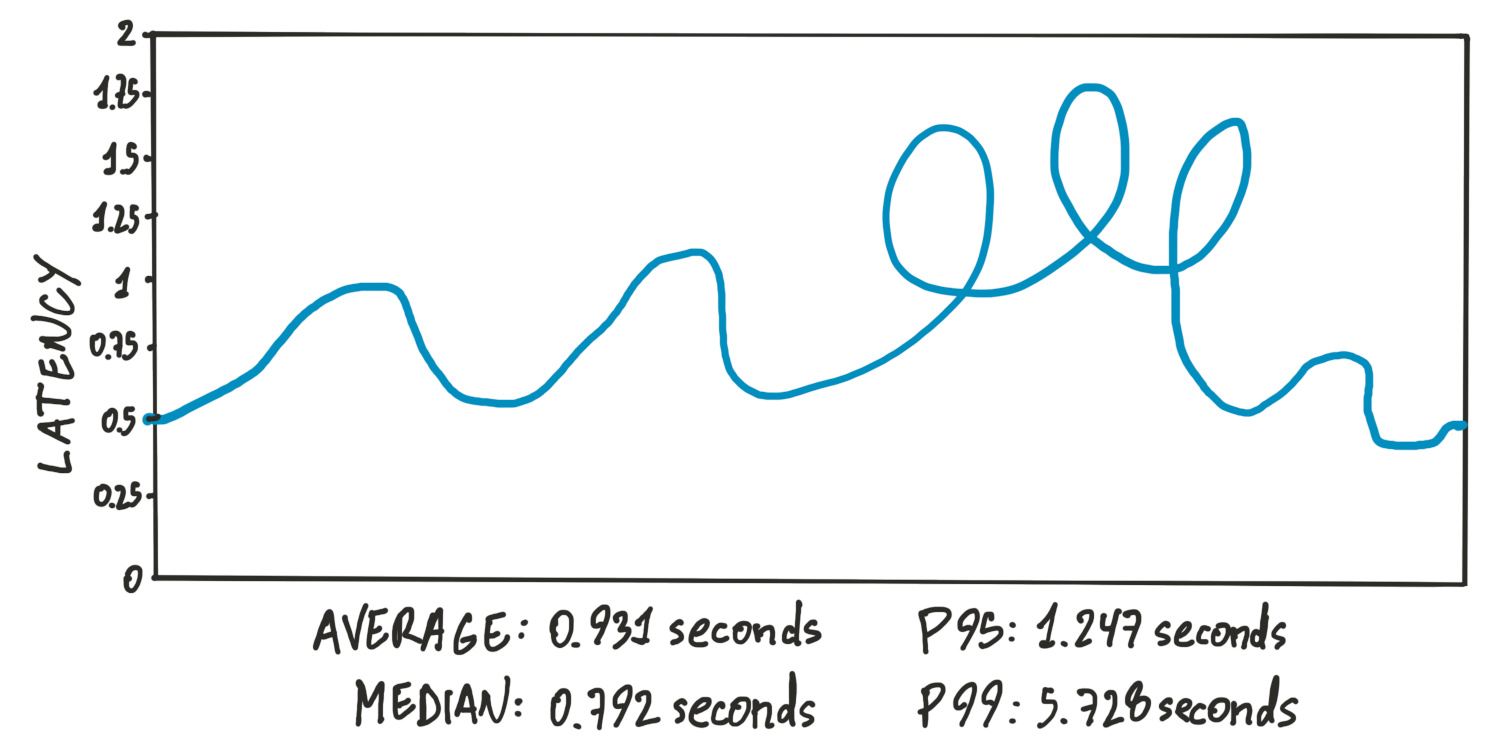
Cando eu comecei a traballar nestes asuntos, eu ollaba moito para a media pensando que sería o valor típico desas métricas. Pronto me decatei de que iso era un erro, porque a media non reflicte o valor típico senón, simplemente, o termo medio.
Cando medimos a latencia, memoria, carga, etc., o valor mínimo de cada medida é cero, pero o máximo pode chegar ata o infinito, e iso vai crear un nesgo cara a arriba no valor da media. Como ilustración, imaxinade que tedes cen mostras con 10 milisegundos de latencia e unha soa mostra con 100 segundos: isto resultaría nunha media de 1 segundo de latencia, que non é un valor representativo nin nada.
Logo, como non valía a media, comecei a ollar para a mediana, que é o valor intermedio (inferior á metade das mostras e superior á outra metade). A existencia duns poucos valores elevados de máis non afecta tanto ao valor da mediana (no exemplo anterior sería de 10 milisegundos), así que parece un bo número para o que ollar.
Porén, a mediana tamén ten os seus problemas. Imaxinade que tedes 51 mostras de 10 milisegundos e 49 de 100 segundos: neste caso, a mediana sería de 10 milisegundos, pero case a metade das mostras tería unha latencia imposible de aturar.
Para evitar este problema, comecei a ollar para o percentil 95 (o 95% das mostras é inferior e o outro 5% é superior). Se o percentil 95 da latencia é un valor aceptable, isto significa que o 95% das peticións vai ben.
Como imaxinades, o percentil 95 tamén é problemático porque ignora o que lle ocorre ao 5% “peor”, e o 5% de calquera cousa non é pouco. Por exemplo: aceptariades que a páxina web da vosa empresa funcionara ben 23 horas no día pero fora inaccesible na hora restante? Seguro que non, verdade? Pois 1 hora é algo menos que o 5% dun día…
Parei de ollar para o percentil 95 e comecei a ollar para o percentil 99. Chegaría con isto? Podo centrarme na experiencia que recibe o 99% das peticións e deixar de lado o que lle ocorra ao outro 1%?
Pois non, non podo descoidar ese 1%. En primeiro lugar, o 1% non é pouco: o 1% da poboación mundial vive en Alemaña, e Alemaña non é un país pequeno. En segundo lugar, non podedes pensar que os sucesos que ocorren o 1% do tempo só lle acontezan ao 1% dos vosos usuarios.
 “Xa ía sendo hora de que alguén pensara no 1%.”
“Xa ía sendo hora de que alguén pensara no 1%.”
Nunha aplicación web moderna, unha sesión normalmente consiste en moitas peticións web. O número exacto depende de para que sirva a aplicación e de como estea deseñada, pero para este exemplo, podemos imaxinar unha aplicación na que a sesión típica contén 100 peticións.
Agora imaxinade que o 99% das peticións funciona correctamente pero o 1% falla totalmente. Cal é a probabilidade de que un usuario vexa un fallo na súa sesión?
A resposta é: o 63% das sesións van ter un fallo. Isto só afecta ao 1% das peticións, pero como cada sesión ten 100 peticións, a probabilidade de que algunha desas peticións teña un fallo é moi superior á probabilidade dunha soa petición.
(É útil saber isto de cabeza. Se a probabilidade de que aconteza un suceso é 1/N e facedes N intentos, a probabilidade de que iso ocorra polo menos unha vez tralos N intentos é o 63%.)
Se tedes algunha vez un caso no que “todo o mundo se queixa” e “isto afecta a menos do 1%” ao mesmo tempo, aquí tedes a resposta.
Logo, se a media non é útil, a mediana non serve e os percentís 95 e 99 levan a engano, que debería ollar?
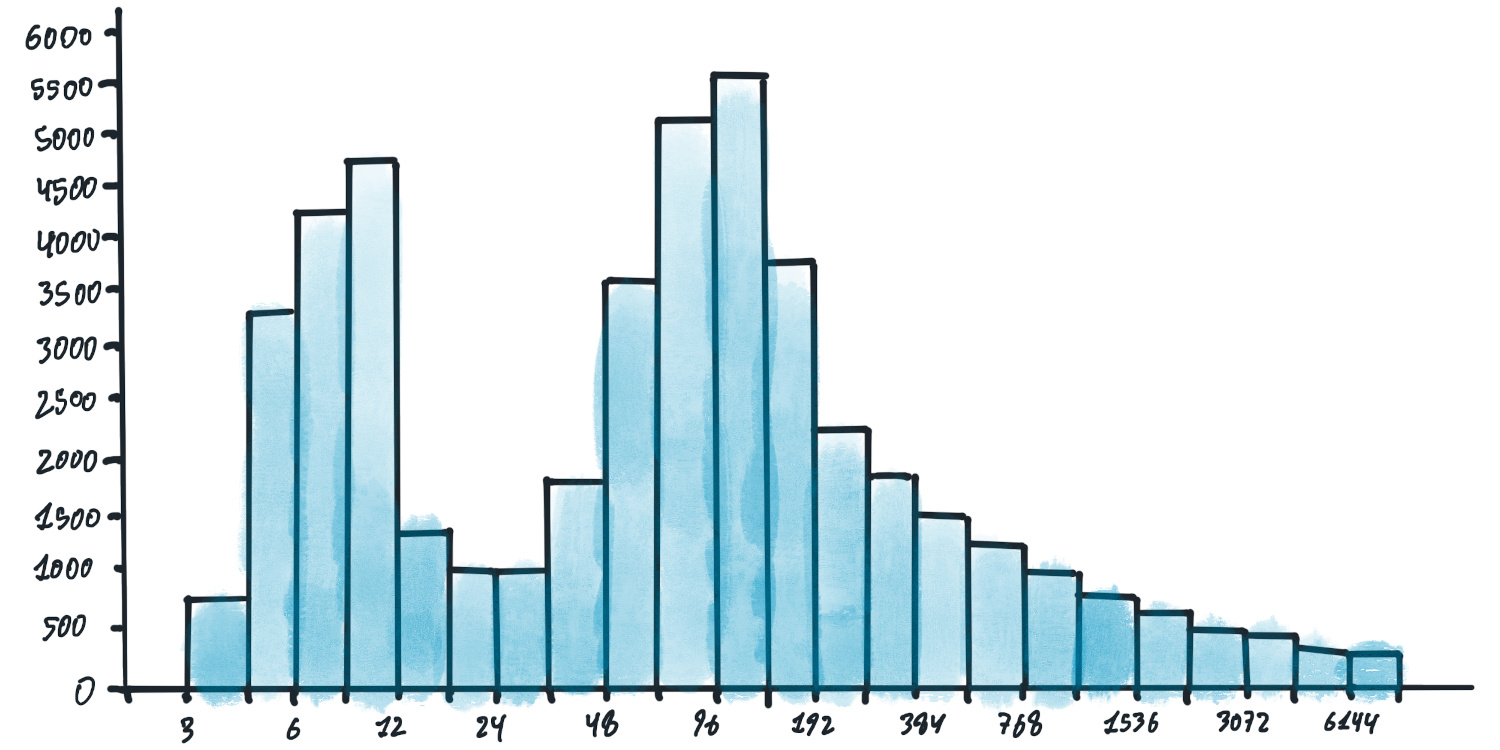
O que debería ollar é un histograma: unha gráfica de barras que me di cantos valores entran en cada categoría. Por exemplo, un histograma de latencias tería unha barra para 0-5 milisegundos, outra para 5-10 milisegundos, etc., e dunha ollada podo ver a distribución de latencias.
Isto dáme moita máis información que a media, mediana ou calquera percentil. Neste histograma podo ver que a distribución é bimodal (hai un grupo de peticións arredor de 10 milisegundos e outra nos 140 milisegundos), que ten unha “cola longa” (un número apreciable de peticións con latencias elevadas) e que a latencia mínima é de 3 milisegundos.
Algúns sistemas de monitorización teñen “mapas de calor” (“heat maps” en inglés), que veñen a ser secuencias de histogramas, e así vedes como evoluciona a distribución das vosas métricas co paso do tempo: se hai horas do día nas que a latencia mellora ou empeora, se aparecen segundos (ou terceiros) picos, etc.
Probade a sacar esta información cun só número.